![Visualizing Ecommerce Website Structures [50M Pages Crawled]](/content/images/size/w500/2020/02/Visualizing-Ecommerce-Website-Structures-50-Million-Pages-Crawled.jpg)
Much like the architectural design of a building, website structures lay out the overall anatomy of a website - How one page links to another and the relationship between those pages. The objective of these structures is to meet user expectations and help them find what they're looking for, with minimal effort.
Why is website structure important?
A well structured website has better discoverability i.e., users can quickly find what they're looking for, enabling a good user experience. A good UX leads to users spending more time on the site, therefore, better conversion rate. Google loves websites that provide a good experience to users, and these sites rank higher for relevant keywords in search results.
A decent website structure also helps Googlebot understand the topical relationship between pages on a site by analyzing links. Internal and external links are pathways for Googlebot; it allows Google to map out and navigate the site.
Without it, search engines struggle to understand what the site is about and that impact ranking.
So when you're building a website, you're not just building it for users, you're also building it for search engine crawlers.
Crawling & Visualizing Ecommerce Websites
I spend eight weeks crawling dozens of ecommerce websites across different industries with one goal in mind - create beautiful visualizations of website structures to understand what is required to create organized and navigable structures for both humans and search engines.
The first issue I had to sort out was the software/hardware stack; both were hopelessly inept for the mission. It was time for an enterprise-level upgrade.
Here's the stack I used -
Hardware:
- 24core, 64GB RAM, 1TB SSD Google VM
Software:
- Gephi for Network Analysis
- Dataiku & Python for data cleansing
- Screaming Frog SEO Spider (SFSS)
- Debian 10 OS
- Adobe XD for creating the visuals
One of the biggest blockers for this project was not being able to clean the CSV file generated by SFSS with Excel. It has a limit of 10M rows and most of these CSV files had 50M+ rows.
After some sleepless nights and lots of coffee, I stumbled upon Dataiku and it was a lifesaver. With a simple recipe in Dataiku and a little bit of Python, I was able to clean data with 100M+ rows in a single file, with ease.
To begin this laborious pursuit, I handpicked 15 popular ecommerce websites, from small(<10K pages) to Amazon(∞). Not all of them made the cut though, turns out you cannot crawl Amazon and BestBuy. Who knew?
It's not because of the reasons one might think - No IP blocking or limiting crawl rate(at least not until 10M pages). Their servers are capable of handling 10K concurrent users so a measly crawler is not going to cause any harm.
The issue is the size of these websites. Amazon, for example, has 119M products and that product page data alone would be >2TB.
If you're a curious ninja looking crawl data and don't want to start from scratch, my partial crawl file of Amazon should help. It's 10M pages and 96GB.
Then there are websites that restrict crawlers.
This was a bummer, I was really looking forward to visualizing some of my favorites:
With crawl rates down to 2 URLs/s, it would take weeks or even months to fully crawl these sites. Can't hold it against them though, it's best to keep crawlers in check unless you're packing some serious server stacks.
Website structures determine how effectively link equity flows to different pages. If the site is not tightly knit then you will end up having orphaned pages which Google will classify as less important compared to other pages on the site, because fewer internal links are pointing to those pages.
This is especially challenging to larger ecommerce websites that are adding new products regularly; on a poorly structured website with lots of categories, new product pages would not receive enough link juice, and as a result, suffer the ranking consequences.
Gymshark

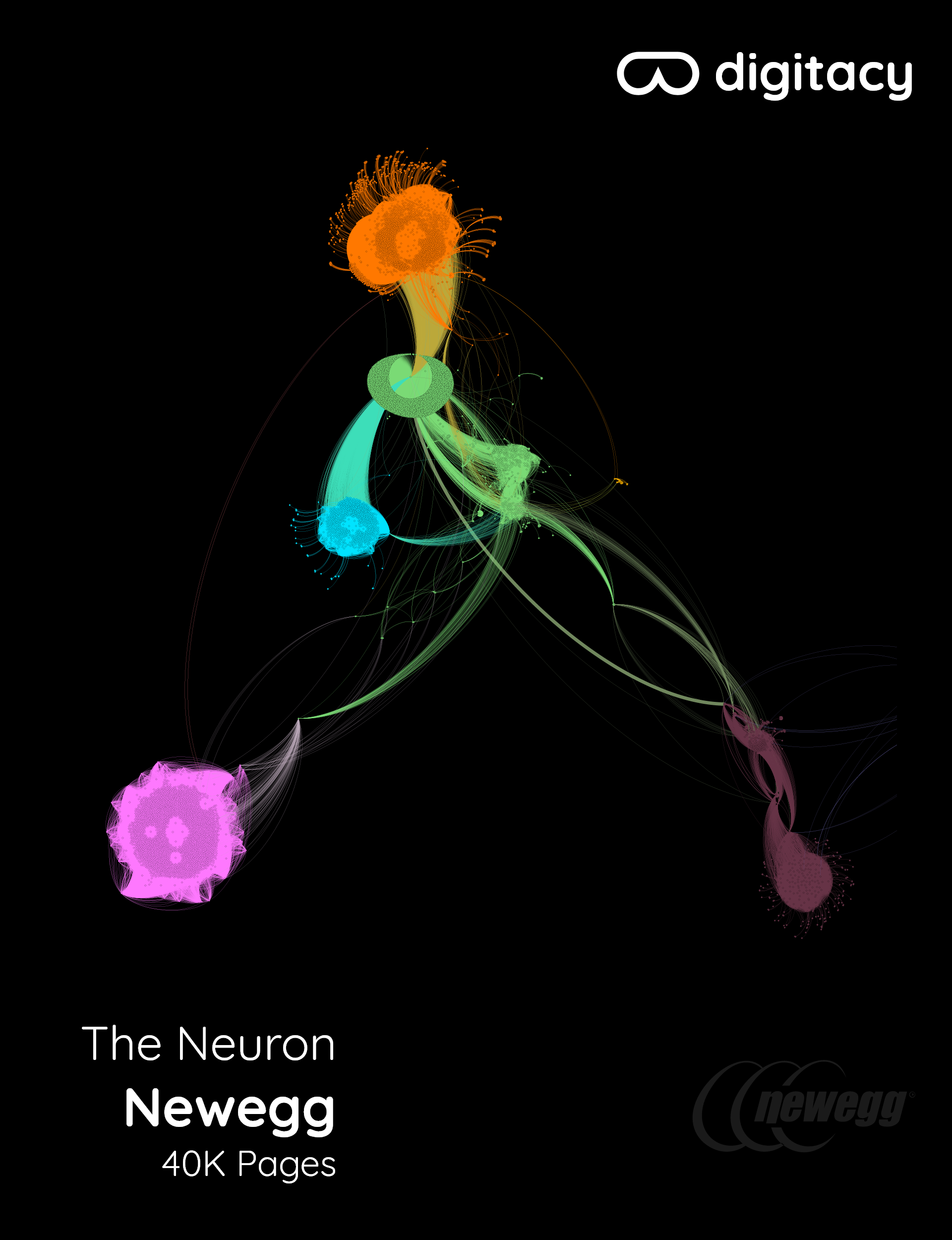
Newegg
Dockers

Louis Vuitton

The North Face

Allbirds

Casper

Forever21

Vrbo

Otto

In retrospect, it would have been wise to focus on small to medium sized websites and ignore anything over 500K+ pages since, at those levels, the complexity of network analysis is ridiculous. Visualizing Otto.com with Gephi took 12 hours on a 24core, 64GB RAM virtual machine, and the structure was still too dense to make any sense out of it.
I have a few more projects in this domain planned, so let me know in the comments if there is something specific you would like to see.